Data collection and labeling is always expensive and tedious. But what if we can ask our friendly LLM to do it for us?
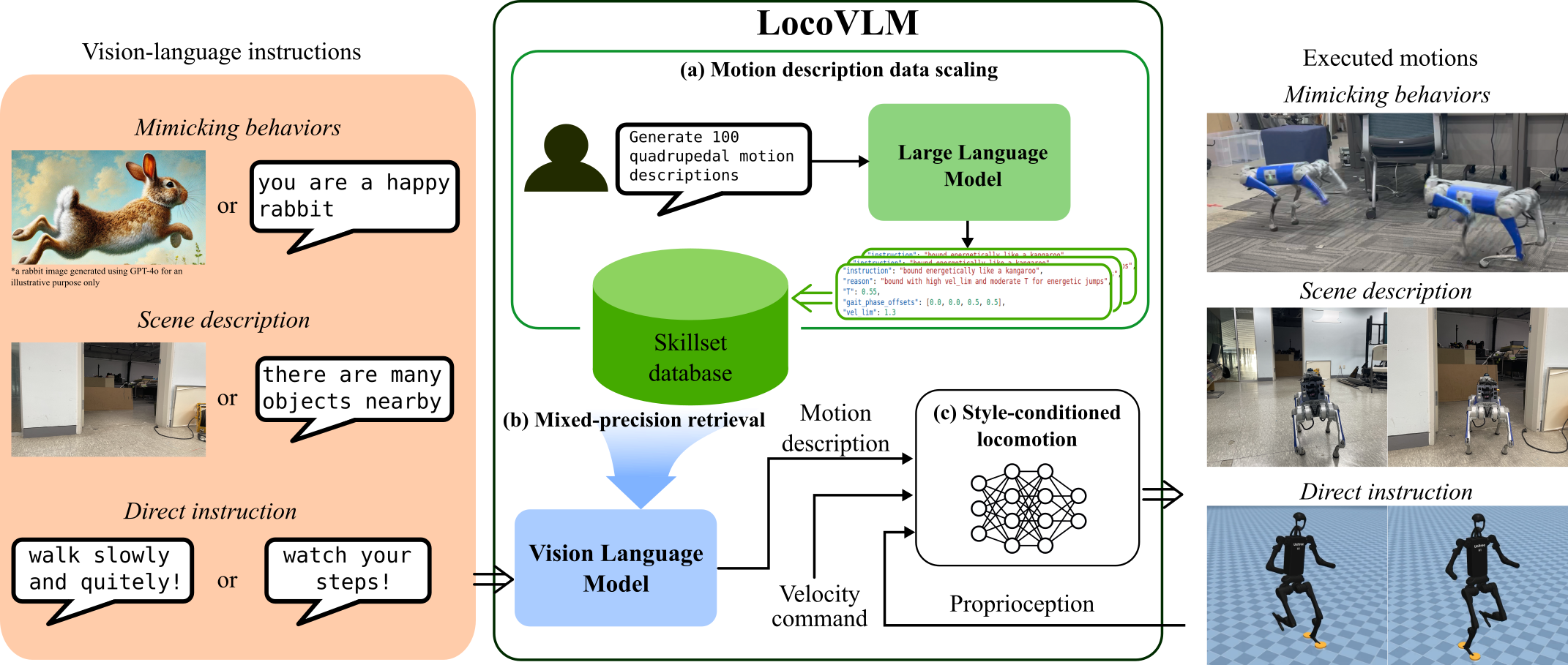
LocoVLM is a versatile legged locomotion adaptation framework that enables quadrupedal robots to follow a given vision and language instructions in real-time while adhering to locomotion safety constraints.
Following gait styles are fancy. But following it too much can be dangerous. What if we follow these gait styles but allow some room for mistake? Here comes the compliant gait tracking, yielding the best of both worlds.
Data collection and labeling is always expensive and tedious. But what if we can ask our friendly LLM to do it for us?
LocoVLM firstly constructs a skillset database that bridges language instructions with robot commands. We prompted a large language model (LLM) to generate instructions, whether it is a mimicking task, scene descriptions, or even a simple direct command. Then, we asked the LLM to utilize these instructions to generate the appropriate robot commands. And voilà, we have a skillset database that can be used to instruct our robot.
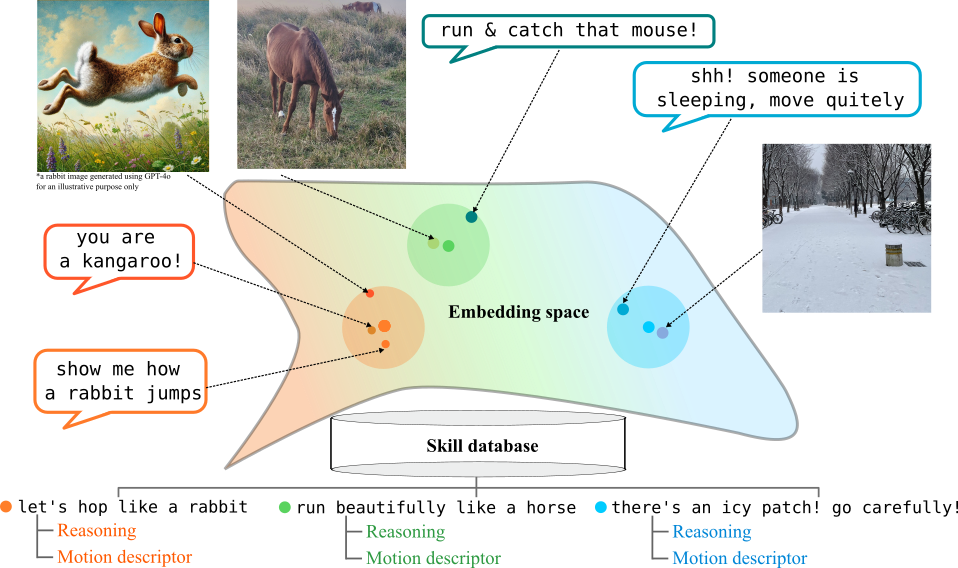
Now that we have a skillset database, how can we make use of it?
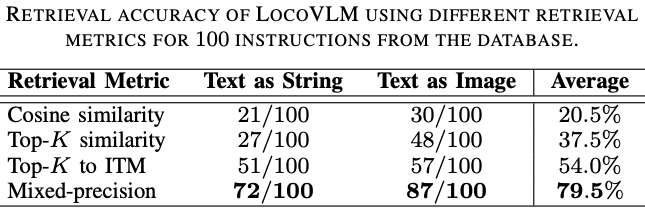
We used BLIP-2, a vision-language model, to ground the language (or image) instructions to retrieve the corresponding robot commands from the skill database. We proposed a novel mixed-precision retrieval method that balances retrieval speed and accuracy.

As easy as 1, 2, 3! Simply train the compliant style tracking policy and you can use the same skill database to other embodiments. (Of course you can make more specific skill database too!)